(This is a recap/review of the 2020 MIT Mystery Hunt, which happened this last month. Puzzles and solutions can currently be found here. This recap may contain spoilers.)
I haven’t managed to find time to blog recently, which is unfortunate because when I envisioned this third post, the main purpose was to encourage discussion, and I’m not sure people are going to be that excited to opine a month after Hunt. But better late than never, I hope.
[Since I also haven’t had time to post about other puzzlehunts, let me mention that I thought My Little Pony: Puzzles Are Magic was quite good! It had too much MLP-specific content for my tastes (you’d think that’s to be expected, but the FAQ was misleading in that respect), but the puzzles were fun, and the story took some twists and turns in a “GPH Lite” sort of way. Also be on the lookout for Cryptex Hunt 2020, which starts on Leap Day (much like the Revs season) and is apparently a novel.]
Before I totally run out of mental fuel to talk about this year’s Mystery Hunt (and the state of Hunt moving forward), I want to ask some questions that I think I have subjective answers. I have my own answers to them, which I’ll provide in some cases, and some of you may have answered them in your own way in the post-Hunt feedback form, but I think it’s often useful for solving teams to know what other solving teams think, and for teams to know what teams think about what teams think, etc. (Though everybody should keep in mind that the vast majority of Mystery Hunt teams are fairly casual and may not be reading a sparsely updated puzzlehunt blog. Hunt is for them too, so don’t assume any consensus reached here reflects the community ethos!)
I’ll number questions below so that it’s easier to refer to them in the comments.
Q1: Are there too many puzzles?
I loved most of the puzzles and metapuzzles I encountered in Hunt this year and thought the quality and polish was really solid on all of them… but there sure were a lot of them. It felt like a big jump in quantity, although comparing the number of puzzles to 2019, my back of the envelope calculation from a few weeks ago showed there wasn’t actually that much of a difference. Of course, I didn’t solve 2019, so maybe people felt the spike then, and I didn’t notice it from constructing HQ. I did think the average puzzle this year was harder/more involved than the average 2019 puzzle, but again, I don’t have the solver perspective. More teams finished “on time” this year than in 2019 by infinity percent, though teams in 2019 seemed more logjammed by metas, and I feel like in 2020 our team was never stuck for long on metapuzzles.
The traditional discussion in this realm is “when should the coin be found?” People have varying opinions about this: an earlier first finish means more teams will get to see the entire Hunt, but some will have a truncated experience, and a later finish means fewer teams will get a satisfying conclusion. But even if you agreed on a target, anyone who’s constructed Hunt can tell you this is something that isn’t purely a function of number of puzzles, and also something you’ll never be able to completely control. Actual Hunt teams are impossible to accurately replicate/simulate in testing, and I’ve helped write Hunts were the coin was found much earlier than intended and much later.
In any case, you can probably guess from my Part 1 post that I would have liked Hunt to be a round or two shorter so that my team could finish. I probably would have endorsed aiming for fewer puzzles in 2019 too, except that the structure we chose needed a lot of puzzles to support it… having metas split between rounds isn’t interesting unless you have a lot of connectivity between the rounds. Structural innovations are something valuable that set Mystery Hunt apart from other puzzlehunts for me, and sometimes those innovations require a large size. But at the same time, a long stretch of Hunts with many many puzzles is inevitably going to lead to an increase in average team size. And that’s something that (a) may not be sustainable on a campus of fixed size, and (b) makes it hard for casual student teams to get involved, and given that Hunt lives off of MIT resources, they’re the teams we owe the most to. More on that in a bit.
Q2: Should every team see every puzzle?
When we designed the “Santa curve” for 2019, one of our goals was that every team, regardless of progress, should have every puzzle unlocked at least an hour or two before close of HQ. We made pretty steady progress this year, and as a result I didn’t realize until afterward that (as far as I’m aware) Left Out didn’t time-release rounds*. This meant a team that didn’t solve a lot of puzzles early probably never saw the Outer Lands and missed a large chunk of story and innovation.
*[Edited to correct myself: As Wei-Hwa points out in the comments, my “as far as I was aware” statement was incorrect, and rounds were in fact time released. I think the main reason I gathered they weren’t is that three of the four largest rounds were batch-opened at once right around when the coin was found, so the isolated bits of information I heard from teams well behind the curve was that they got an impression of “Okay, folks, competitition’s over, now the rest of the Hunt is open.” I would still argue that given the size of these rounds, opening them at 1pm on Sunday makes it impossible for those teams to see all of the content in them, and opening them all at once diminishes the discovery effect, so the Q2 debate is still relevant to this Hunt. But I apologize for my false assumption above.]
There’s certainly a debate to be had about this, and the big unknown variable is trying to predict what will make casual teams happiest: focusing on early meaningful goals, or getting to solve whatever they want. There’s an easy argument that if you give teams all the puzzles eventually, they can make this decision for themselves. But there’s a counterargument that teams that are only solving a few puzzles may be overwhelmed/dispirited to have a pool of 100+ puzzles to wade through. Some constructors would probably like to encourage those teams to solve a meta (maybe their first ever!) and keep them in the shallow end so they can do that. On the other hand, some constructors probably want as many teams as possible to see what they’ve written, especially if they wrote the last puzzle released in the last round…
My own opinion on this probably varies based on the Hunt structure. When a new round or concept is revealed on the Hunt website, I get an endorphin rush, and I want every team to get that rush. So for this year, my preference would have been to have the round openings time-released to teams. (Maybe this did happen, but I gather it either didn’t, or it happened very late.) Within each round, you had to solve puzzles to unlock other puzzles, which means even as a strong team, some puzzles were never opened to us. I don’t object to that. I’d like teams to be able to see what the whole structure looks like by the end of the weekend, but I’m not fixed on everybody seeing every single puzzle. We did that in 2019, but due to the linear release structure, getting everybody every round wasn’t that different from getting everybody every puzzle.
Q3: Where do you put the story?
This is a nitpick, but 2016 and 2020 were the two Hunts I can remember that conveyed major story elements through videos isolated on the website. I take a lot of interest in the Hunt theme and story, but in both of these years, I never felt particularly driven toward the video page. As a result, these were probably the years that I felt least engaged in the story. This is, of course, my own fault, since I could have watched the videos if I wanted to (and the 2020 videos in particular, I discovered later, were adorable). But my interactions with the website and puzzles never really encouraged me to do that.
I also get the sense that a lot of story/theme/aura was conveyed to the people who went to squish pennies after each meta solve. I didn’t go to any of these, and the people who did didn’t tell us much else than that they got pennies. On a large team, a lot of members won’t end up going on any of those trips, especially since some team members like to volunteer for multiple pick-up missions. There was a nice skit when we opened the Outer Lands, and I appreciated that that skit happened in our HQ so that as many people could see it as possible. But it was something we watched rather than something we did, and the plot didn’t have a whole lot of urgency (especially once we established that the park was no longer closing).
I don’t want to send the message that I didn’t like the story or theme this year… I thought the kickoff (even after the wedding) was creative and well-written, and the theme park “lands” structure was intuitive enough that you didn’t need to follow the story to understand how the puzzles fit together. If you don’t care about story, the website and puzzle design made it easy to ignore the story and solve the Hunt. But as someone who does care, it was too easy for me to ignore it too. To paraphrase an argument I remember making to someone on another team I constructed with, Mystery Hunt is a set of puzzles with a story layered onto it, not a story with some puzzles, and so the story will (and should) always take a back seat. But I think it’s worth discussing narrative strategies to immerse solvers in that story as much as possible (without obscuring the puzzles).
Q4: Is phoneless answer confirmation the way of the future?
I dropped a question about this at the end of my Part 1 entry, and a lot of people already commented (as they did on Reddit). I think the question is fairly well-understood, so I won’t restate the problem, but it’s certainly an open question, so I’m including it again here.
I will say this: Virtually all of the people/teams I’ve heard who didn’t like losing the phones are Hunt veterans… I was concerned with the effect on newer teams, and they don’t seem to have had a problem, though by definition they wouldn’t have anything to compare to. And a lot of the veteran complaints have been along the lines of, “We expected to do X and have done X in the past, and we were bummed that we didn’t get to do X,” whether X is using the phone calls to keep team members aware when progress is made, or to check in with HQ, or to make wisecracks. Maybe some more advance notice might have been useful to smooth the transition, and I would encourage PPPGTPPP to let teams know in advance what to plan for next year.
I might get kicked off Setec for saying this, but I actually think the online submission is mostly better (and I especially loved the sound tags on solves). But there was one related issue that might be a dealbreaker. I’ll meet you at Q5.
Q5: How much guessing is too much guessing?
If you’re a regular reader (at least as much as I’m a “regular” poster), you probably remember my ranting about backsolving and THE WOLF’S HOUR in 2019. (I hope THE WOLF’S HOUR will join BE NOISY and RECTION in the die-hard Hunter’s inside-joke file.) I am by no means the most opposed person to backsolving/guessing, but I’m certainly not the least. That said, the captain of teammate wrote a great blog post about their Hunt experience that contained this little nugget: “during the minutes before the hunt started I encouraged everyone to submit a guess as long as they were >10% sure that it could be the right answer.”
The next paragraph begins, “I realize that this aggressive guessing strategy seems horrifying to some teams”… And I would like to confirm that YES, IT DOES. I realize this isn’t how it’ll happen in practice, but “more than ten percent sure” suggests that a team may expect to call in nine or ten answers per puzzle. With no live phones, that’s no longer something that’s going to jam up the lines and prevent other people from confirming answers. But the same post also includes this very relevant graph:
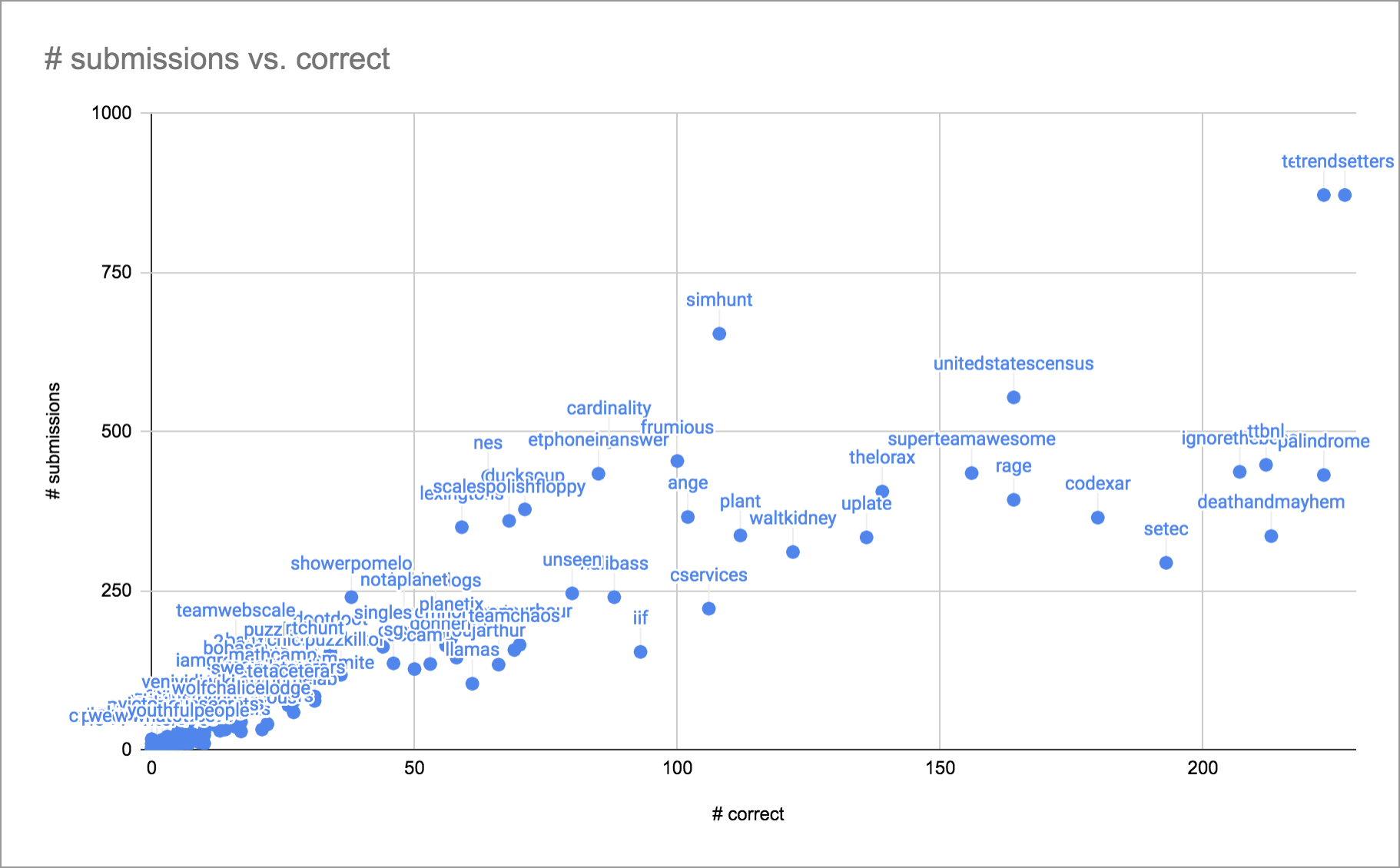
>=D=> >=D=> >=D=> GT >=D=> >=D=> >=D=> (yes, I am going to write that differently every time instead of looking up how to type a damn airplane symbol) is certainly a team to be reckoned with… They have great solvers, and I’ve loved all three Galactic Puzzle Hunts, and I was honestly rooting for them to win (sorry, Palindrome, I know you’ve been waiting) this year. But I find it very troubling that the two teams that guessed answers the most aggressively were two of the first three teams to finish, and in particular, in the first year without phones (and thus without a construction team potentially getting annoyed about answer spamming), the two most aggressive guessing teams had a notable increase in performance. I’m not sure that’s entirely a coincidence.
So here’s the thing. I think it’s up to the constructors to decide what parameters they think are reasonable for solving teams. On one hand, I think those standards should be communicated better to teams, and on the other hand, if teams know the precise standards, it could encourage some teams to engage in “unacceptable behavior minus epsilon.” And I suspect Trendsetters will have a pretty loose attitude about this given their own solving style. But I encourage all Hunt writers to consider that allowing teams to guess aggressively will encourage any team that wants to win to guess aggressively. And that will cause a lot of puzzles to fall more quickly. Which may cause constructors to feel obligated to write more puzzles. At which point I refer you to Q1.
Q6: How should non-student participants (and teams) approach Mystery Hunt?
This question is here for two reasons. The first is that the late-night-visitors-on-campus policy this year was a major event in Hunt history, and it’s worth discussing. The second is that I spent a lot of time before and after Hunt ranting at people on various social media platforms, and I want to collect those thoughts here for the record.
I did not state the question as something like, “What resources should MIT provide to non-students?” because no one creating or participating in Mystery Hunt ultimately has control of that (though the evolution of Puzzle Club is probably the best thing that has happened in years in terms of giving Hunt a stable voice on campus). MIT doesn’t have any obligation to support or continue Mystery Hunt, and they certainly aren’t required to host a large number of visitors on campus for the event. Yet they allow Hunt to use a large number of rooms, both for solving teams and the constructing team, and they also partially fund the event through various avenues.
Based on some of the posts I saw elsewhere and flipped out about, this relationship between Hunt and MIT is not fully understood. People suggested that Mystery Hunt is a vital part of MIT’s educational mission. It’s not. People suggested that Mystery Hunt is one of the biggest events of the year on campus. It’s not. People suggested that Mystery Hunt is a large enough event that Boston and Cambridge should be aware of it and provide support. It’s not. I think it’s a wonderful part of MIT culture, and it’s one of the most important events of the year to me (and has played an outsized role in my development as a human being). But it serves a niche audience, and we should not let ourselves believe the world revolves around that audience.
People also suggested that MIT is paying attention to the event design throughout the year, and so any policy changes they make are through some fault of the construction team. That’s not how this works. If anyone still believes any rule changes for late night HQs this year were because of Left Out, please understand that, in fact, the reason so many rules eventually were left unchanged were because of diligent work by Left Out and the Puzzle Club. I am very grateful for everything they did, especially in the last week when there are a million other things to worry about.
If you are not an MIT student–and I’m including myself in this even though I paid MIT four years of tuition back around the turn of the century–any resources, classrooms or otherwise, that MIT provides you are a gift. The Institute is not perfect (I refer you to a lot of other blogs and news outlets for more information on that), but they are doing the Mystery Hunt community a big favor. The best way to ensure that this favor continues to be done is to remember that, whether you donate to Hunt or not (and please consider doing so), you are a guest on campus. Enjoy the event within whatever constraints are put into place, don’t be entitled, and trust that the people who interact with MIT are doing what they can to include as many solvers as possible.
Sorry to end this post on such a ranty note, but Q6 has been a touchy subject for me this year. With that, I’m going to close the book on 2020 Mystery Hunt posting. If you have thoughts on any of the questions above (or other Hunt thoughts that you don’t have a convenient place to deposit), please respond below, and I’ll see you in the comments.

I’m reasonably sure some rounds were time released eventually, though only the opening puzzles in the rounds. I believe my team got Safari and Creative Pictures time released sometime Sunday morning (but not the last two). I’m not sure if we got any of the inner rounds time released or if we earned them all.
LikeLike
(For context, I’m on a mid-strength team; I roughly consider ourselves one of the strongest teams with approximately 0% chance to ever win the hunt. we usually finish around 14th or so)
Some thoughts:
Q2: Should every team see every puzzle?
I talked about this on another post, but I’m strongly in the ‘yes’ camp. There’s a lot of cool stuff in the hunt and I want to see it, even if we’re not going to even come close to solving it. We missed nearly the entire Pokemon round in 2018 and it sounded like there were some really amazing puzzles and stories there (pee on a stick, controlling your teammates) that my team didn’t have much of a chance to experience. Giving every team every puzzle also solves the problem that teams can become blocked on puzzles that nobody happens to have the appropriate knowledge to solve, or that teams just can’t find the right ‘ah-ha’ to progress. We’ve had a couple instances where we’re hard blocked on 3-4 puzzles and we sort of just sit around and twiddle our thumbs waiting for somebody halfway across the world to solve the Listener so we can open more puzzles. In 2019 once we hit the Santa unlocks we knew we’d never be stuck for more than an hour or so.
Q3: Where do you put the story?
I think this depends heavily on what the story actually is, so it’s hard for me to put forward much here. I will say that the midway runarounds from 2017/2018/2019 were all great and did a lot (birthday town, every core memory (not really ‘midway’ but same idea), and the character ‘runaround’)
Q4: Is phoneless answer confirmation the way of the future?
I can go either way on this. I did genuinely miss callbacks, but not so much that I’m particularly saddened by their loss or anything. I suspect the benefits of automated confirmations are mostly felt by the running team (ie freeing up manpower to put elsewhere), so LO/other constructing teams are probably best suited to talk about this.
LikeLike
Giving a team access to all puzzles is not, inherently, a solution to “we’re stuck on all the puzzles we have”. A team could have access to all the puzzles, and still be stuck on the ones they haven’t solved. For example, in last year’s Galactic Puzzle Hunt, I had all the puzzles open and I was stuck on all of them, because they were all in Puflantu.
It also isn’t the only solution. This year, were you ever in the situation where you were twiddling your thumbs?
LikeLike
“For example, in last year’s Galactic Puzzle Hunt, I had all the puzzles open and I was stuck on all of them, because they were all in Puflantu.”
Only the metapuzzles were in puflantu, which were 4 out of 40 puzzles. If you’ve successfully solved 90% of a puzzlehunt, you are not the audience that time-release mechanisms most need to take into account.
Hinting is, of course, another solution to pinch points, and it’s a good one that should certainly not be replaced entirely by additional puzzle releases. But there are likely some teams, especially casual ones, that would prefer to abandon puzzles they’re not into and play with others, rather than be hinted through the ones they don’t want to feel like solving. My main question is to what degree the constructing team should impose their will in this case… if a team asked ten minutes in, “Can we just have all the puzzles?” you’d surely say no, so there’s clearly a line, but I suspect participants differ on where that line is.
LikeLike
I completely agree with what you say here. My point was that Daniel was overgeneralizing in his statement that opening up all puzzles will always be a solution to the “stuck on everything” scenario.
(Another example is when the team just isn’t having fun at solving the puzzles in the Hunt. If a small team is only going to enjoy 10% of the puzzles in the Hunt, and they’ve done them all because they’re all at the start, opening up more puzzles won’t help them.)
LikeLike
You’re incorrect about Left Out not time-releasing rounds. Each land had a time-release when the land became available — but only the initial set of puzzles in the land were released (the precise number was different between lands). The schedule was as follows:
1pm Fri – The Grand Castle, Storybook Forest
11pm Fri – Spaceopolis
7am Sat – Wizard’s Hollow
1pm Sat – Balloon Vendor
7pm Sat – Yesterdayland
11pm Sat – Big Top Carnival
7am Sun – Creative Pictures Studio
1pm Sun – Safari Adventure, Cascade Bay, Cactus Canyon
Note that the original design was every 6 hours, but all the 1am unlocks got changed to 11pm when MIT told us that nobody could be on campus from 1am-7am.
LikeLike
Corrected above. Thank you for clarifying quickly, and I apologize for spreading a false assumption in the interim.
LikeLike
2017 had an interesting approach to seeing all the puzzles, where the full hunt was opened as soon as the coin was found. (Of course this is only relevant if the coin is found before the end of the scheduled time.) I thought this was a nice idea in theory but in practice it took away from some of the hunt structure. Notably, our team opened the Pokemon round last and hadn’t made much progress there when the coin was found, so the entire “solve a puzzle, get the evolved version” concept was lost.
I do think “when the coin is found, teams can opt in to opening the whole hunt at once” is a worthy idea, especially for hunts with a more homogenous structure like 2018.
LikeLike
(By the way, I agree that Puzzles Are Magic was fun! But wow did the metas make me think about your comments after GPH last year about metas that are locked until you have many feeders solved — I’m pretty sure both of the main metas would have been solvable with 0 feeders.)
LikeLike
Meta 2 was definitely solvable with zero feeders, given that we didn’t figure out how to use the feeders until after we’d solved it!
LikeLike
Coincidentally, we just finished putting up the wrap-up for Puzzles are Magic, and it talks directly about this point.
The short version is:
1. We were new to meta construction and decided very early to use a hard unlock gate, because it would make building the metas easier. (This was extra true for a 6 puzzle round – the 66% threshold is 4 puzzles, the 50% threshold is 3 puzzles, we weren’t comfortable with teams finishing a round after 3 puzzles, and we weren’t comfortable with teams needing 5+ puzzles to advance either. Hitting the 4-puzzle mark exactly sounded absurdly difficult without a hard unlock gate.)
2. Given how serial everything was for story reasons, we wanted to make extra extra sure that no one got stuck on our metas.
3. In the process of testsolving the metas, we focused exclusively on difficulty, and somewhere along the way we lost track of whether our metas still felt like metapuzzles.
Having thought about it a bit, I don’t think either meta’s design had an easy design fix that would fix the 0 feeders problem. We’d have to change the extraction mechanisms for both in fairly drastic ways.
I’d say my overall thoughts are that any creative endeavor will have something slightly wrong with it, and given a do-over, the metas are the first thing I’d try to fix. But I don’t feel too bad about it, and too-easy metas was definitely better than too-hard metas.
LikeLike
Yeah, that was definitely more of an observation than a complaint 🙂
LikeLike
relating to both Q4 andQ5:
As a member of Attorney (see Dan’s first 2020 post), aka US Census (per the graph, the fourth-guessiest team in this year’s Hunt), I’ll echo what Erin and Brandy said in their comments to your first post. Our team was behind the “leaders” but still significantly ahead of the small teams that benefited from the hinting and other casual interaction. As I’ve read various accounts of the 2020 Hunt, a lot of them seem to be describing very different experiences from ours, and a lot of this difference seems to be in answer-handling, guessing, etc.
The automated system makes no distinction between blind guesses, 10%-confidence guesses, submissions purely for humor value, backsolve attempts, legitimate attempts that are close/reasonable, and legitimate attempts where the solving team is still missing an aha. During Hunt we weren’t aware to what extent–if at all–our submissions were being seen by a human, even in a general how-is-this-team-doing sense. LO and other hunters have talked about having their lockouts/queues proactively cleared, or engaging with the hint system/wellness visits instead of spinning their wheels…we didn’t get that. We spent hours (due to lockouts) sending legitimate answer attempts that were variants of PALMTREE / DESERTISLAND / etc. (They did eventually visit us for that one, but only after we were stuck for long enough that we submitted an answer promising them mojitos if they accepted our answer–which was the only reason we found out that there was occasionally a human looking at the submissions.) Similarly, we had to proactively contact them when locked out for similar reasons on Refreshment Stand.
One thing about phone confirmations is that they create frequent, low-key, person-to-person contact between HQ and teams, which would have previously been the venue for a lot of this to be ironed out. I’m not vehemently against automated confirmations, but there didn’t seem to be a replacement for this level of contact–at least not for our team.
LikeLiked by 3 people
I agree that Puzzles Are Magic was a very fun puzzlehunt–I very much hope the organizers run another one.
The question about backsolving will always be a messy process, because while you can talk ethics all you like, in practice it is very hard to enforce. Firmly telling a team to stop and ignoring them has worked, conventionally, but I think earlier discussions about this subject on the blog has brought up all the problems with it. Some Hunt teams are too spread out, across remote solvers and on-campus, to know if one person is spamming like crazy. And I have read experiences in the past about teams with solvers who are trying legitimate answers and are yelled at HQ because they think they are backsolving. That is never OK, and leads to broken feelings.
I think the main point I’m trying to make is, at some point, you have to quantify how much backsolving is too much. Online answer submissions with a number of hints allowed in a time period is a valid solution. People at Hunt will always be trying to short-circuit puzzles or back solve them with egregious guessing—I noticed in an earlier post you guessed the answer for Film Clips and got it right. Your main concern with aggressive guessing seems to be that teams can finish earlier, which can lead to larger-scale Hunts, but does the online answer checker enable that much?
I do miss the calls to HQ, but in reflection I do have to admit it is a *considerable* amount of manpower for the organizing team. We’ll have to see what Galactic Trendsetters decide to do; I do agree with you that they should announce it in advance, so teams know if they need to bring a team phone or not.
The hiccup with MIT administration and the Hunt was very big this year. I hope the future of the Mystery Hunt is bright, but either way I am grateful.
I was surprised to see you barely talk about the metapuzzles this year. What did you think about them? Specifically the Safari Round and the Emoji round, but I’m also curious to hear your thoughts on the penny supermeta, which bottlenecked leading teams for many hours.
What rules, or guidelines, do you think writers should follow in creating puzzle hunts to successfully incorporate the theme/story into the hunt itself, instead of making it an isolated element? I am genuinely curious. Maybe a future blog post idea?
LikeLike
Re Film Clips: We were in a situation where we had three or four puzzles unsolved, and we knew from the meta that the answer to one would be an envelope. Calling in that answer for the puzzle we knew was related to an envelope we had collected felt like a highly educated guess. So that didn’t feel egregious to me, but mileage definitely may vary.
Similarly, if a team had had two puzzles unsolved in Halloween and knew one had the answer THE WOLF’S HOUR, I would have had zero problem with them trying it for one and then the other. It was the teams that had it early and tried it for everyone of seven or eight puzzles that felt like abuse. One “solution” for those that think this is a problem is just to penalize all wrong submissions, and teams can decide for themselves whether a guess is worth it. But as dwilson says above, this is a problem when the system can’t distinguish between honest misunderstandings and system gaming.
I liked the metas this year, and the main reason I didn’t blog about them (I was planning to) is I was asleep when most of them got solved! I helped most with the Carousel and the Texas Panhandle… the latter (or at least the alphanumeric piece of it) was one of the only metapuzzles ahas I distinctly remember getting. They were rarely obvious and yet smooth enough that we were rarely staring at one for hours trying to get unstuck, which is a big plus in my book. As for the penny supermeta, since Setec didn’t get to it, I didn’t spend enough time thinking about it to have an opinion.
LikeLike
Oh *now* that you’ve finally been on a team that didn’t see the endgame, you agree with me that maybe Hunts have gotten too long??
LikeLiked by 2 people
I don’t think my opinion has really changed… I thought the coin was found too early in 2017 (I know you thought it was just fine, and you’re not the only one, and it’s a defensible position) and I thought it was found too late in 2019 and 2020. There’s a ton of gray area in the middle there for people to have differing opinions.
One unintentional negative effect I think 2017 may have had is that, as I blogged three years ago, most of the reasons it was completed so fast was that the metapuzzles were too short circuitable due to presentation, and it was possible to swamp the board of you solved metas fast. But it’s possible that teams now look at that and say, “A 145-puzzle Hunt is going to end super early.” Ours did, but that doesn’t mean you need 180 to keep competitive teams busy for more than a day.
LikeLiked by 1 person
While I’d agree that the coin was found too late in 2020, I think that the main reason is because of our misprediction regarding the solveability of the pressed-penny capstone/supermeta. That one puzzle, IMHO, made a difference of 7 hours. So I’d be loathe to draw any correlative connections between “total number of puzzles” and “hunt ending at a good time”, as far as 2020 is concerned.
LikeLiked by 1 person
Reading the comments about the policy change on answer callbacks and on the fairness question surrounding how lockouts were implemented, I wonder if one is a solution to the other.
If your team just used up the last available answer submission (for now), instead of simply being told “Incorrect” perhaps teams should get a message “Please contact HQ”. That lets a human review their answer history and make a fairness call on whether the wrong answers should have been marked as legitimate, and also provide the emotions-running-too-high checkin.
(I know that on Ox, one of my favorite puzzles from this year, we called in all three answers wrong once and then right, because there was inconsistency about whether to call in the pre-transformed or post-transformed answer. I would have been very upset if that resulted in us being locked out.)
LikeLike
I ran with Duck Soup this year, as team that had almost all inner-park metas solved, 68 solved total. I ran last year with a lower solve team, but both times as a remote solver, so my answers will be seen through that lens:
Q1) I think that to have huge themes you want a lot of puzzles, but just looking at the last few years I do think there are still too many. Our team probably had at least 40 solvers, and realistically the only way we could’ve even made it to safari adventure was adding another 10-20 people. I understand that lowering the puzzle count will make big teams finish quick, but I think if it happens 2-3 years in a row then team sizes will shrink down and the solve times will stretch back out.
Q2) The one benefit of not seeing all the puzzles until late is that it forced our team members to focus on the inner lands and get those metas solved. In this case there wasn’t really a mid-point runaround so it wasn’t as necessary, but once other lands open up teammates tend to go work on whichever puzzle interests them. This can be seen as good for the individual puzzler, but not as good for overall team progress. Personally, I am fine with any method, but would like the ability to at least see every puzzle before the event closes (to look at before the final site is up).
Q3) As a remote solver I definitely enjoyed the videos, as I don’t get to see any on-site visits. It seems like you got 3 videos before the outer worlds, then one more at the end, so I think there could’ve been more added in the outer lands to feel like you were making progress through the story. The event is mainly on site, so I think a good mix between media like videos as well as on-site visits are a good medium.
Q4) As someone who has done one year of phone submissions and one year of online submissions, I think online submissions are definitely better. The ease of logistics is too good of an advantage to switch back in my opinion. Most smaller teams don’t have any real staffing overnight, so if a solver wants to work overnight either online or in a hotel room, they either have to change the phone number or wait until morning to submit. The sound bites also acted as a good morale booster, and let you keep track of how your team was progressing over time.
Q5) Our organizers had the rule “Only guess if you are confident, and don’t spam guesses”. Now of course everyone’s range of what confident means is quite different, but I feel the answer limiting was sufficiently punishing. Tangentially related, I think that an online answer checker should also confirm partials, which the majority of other hunts now do as well. I can’t tell you how many guesses we wasted on the partial for Spaceopolis only to find it was only a partial and not even the final answer.
Q6) As a team with no MIT students, it’s definitely unfortunate to not have any overnight space. At the same time, I totally understand why this is a thing and think it’s completely within MITs bounds to enforce this rule. Hopefully if this stays the same going forward MIT will let us know ahead of time, so that we can better plan around it.
LikeLike
We had some significant discussion on Left Out as to whether the answer checker should confirm partials, to the extent that there were even several puzzles where we had written specific responses to specific partials.
Ultimately we decided that since it was Mystery Hunt tradition to not confirm partials and that we weren’t sure how the automated answer checker would be received, we decided not to confirm partials to avoid “bridge too far” responses.
There was one type of exception, though, which is that if a puzzle answer was a legitimate solution to the puzzle but not the answer needed for the meta. For example, if a puzzle solved to the partial phrase “BAND WITH JOHN PAUL GEORGE RINGO” and the answer “THE BEATLES” was submitted when the meta needs “BEATLES”, the checker would respond something like “That is correct but not the answer we are looking for. Please submit BEATLES.” (Note that if the partial phrase was “BAND WITH JOHN PAUL GEORGE RINGO SEVEN” then “THE BEATLES” would just be incorrect, with no special message.)
LikeLike
I would argue that any puzzle with that clue phrase is a bad puzzle which needs better editing. If a puzzle “legitimately” has a second a solution, fix *that* problem, not your answer checker.
LikeLike
Sometimes there are tradeoffs. Let’s say that “BAND WITH JOHN PAUL GEORGE RINGO” uses all legitimate Scrabble dictionary words in the puzzle-solving, while, “BAND WITH JOHN PAUL GEORGE RINGO SEVEN” requires a bunch of obscure words that are only in specialized dictionaries. Or maybe the extraction uses a 3x3x3 cube and so naturally lends itself to a 27-character phrase but not a 32-character phrase. (As an exercise, see if you can write a short clue phrase that legitimately solves to BEATLES and not THE BEATLES without making reference to answer length or the word THE. It’s actually rather tricky.)
Yes, all other things being equal, it’s better to have the puzzle give a clear unambiguous answer. But sometimes all other things are not equal, and it’s not worth sacrificing certain other bits of puzzle elegance just to avoid a minor ambiguity like that.
Note that, as far as I know, we did not actually use that aspect of the answer checker in the actual 2020 Mystery Hunt — we managed to iron out those problems in puzzle editing, or we made the judgment call that specific answers that other more lenient checkers might accept were deemed incorrect (such as a palm tree emoji instead of a desert island emoji). But just because you don’t expect your system to fail does not mean it’s a bad idea to design your system to handle failure points gracefully.
LikeLike
I mean, you can also just draw some blanks or spell out the distinction, like you did in The Trebuchet.
LikeLike
Yes, you could. But if your puzzle is a physical artifact or a live interaction, sometimes there’s no good place to put those blanks. And sure, I bet you could come up with some way to handle those cases too… but I think it’s silly that we’re getting into some sort of puzzle-based escalation war here. (Not to mention that we are pretty much rehashing a lot of similar discussion we had internally in Left Out when developing the automated answer checker.)
You are free to disagree with the philosophy that the answer checker should handle the case of “solver sends an answer that is technically correct but will screw them up on the meta”; I’m just reporting that that is what we did in 2020. Sure, stuff that hits this case is stuff that should have had better editing, but if you think that editing puzzles by a large group of people under a strict deadline is infallible, then you have a lot more confidence in your team than we did.
LikeLike
I think I struck a nerve there — sorry, I mostly just meant to point out that it was an issue your team solved well via other means! (I don’t have super strong opinions about answer checking for partials and unlike you and Erin have no actual experience running a hunt!)
LikeLike
I think David and Erin are both bringing up totally reasonable points (with varying levels of tact), and keep in mind that discussion on this blog is useful for establishing what future teams should consider doing, not only what Left Out hypothetically should have done. (After all, this Beatles clue phrase puzzle doesn’t even exist, so let’s all calm down.)
I am also in the camp that believes that if a puzzle has an ambiguous answer, it should be resolved in the puzzle presentation rather than the answer checker. Mileage may vary, but I’m not offended if, in order to do that, the puzzle includes something like “(Note: The answer to this puzzle is one word.)” Even if the puzzle is a physical object, in the Mystery Hunt there’s generally a web page pointing to it, and you can always put text on that page.
As for the related issue of verifying partials, I know this is a west coast east coast culture war, but I’m against verifying partials in Mystery Hunt. My argument is that it encourages teams to throw everything they can think of in to the checker to see what happens, which encourages aggressive guessing, and as noted above I have issues with that. I do think partial verification makes more sense in an environment like DASH or The Game where you’re only solving one puzzle at once, and backsolving is less likely. For Mystery Hunt, I think the answer checker should just check answers, and if it needs to do more, the puzzle constructor should address that up front.
LikeLike
Hmm, I’m genuinely surprised at the “puzzles need to be fully unambiguous” stances here. Going with the beatles example, I’m struggling to see a meaningful difference between putting a note into the puzzle (“The answer is one word”) versus having some appropriate message when somebody submits THE BEATLES. Both those achieve the same goal with approximately equal elegance (or lack thereof).
I mean, obviously the best possible world is the one where the answer falls out completely unambiguously with no need for clarifying messages at all. But given that’s not always possible, why would it matter if the clarifying message is in the puzzle or the checker?
LikeLike
Asher: I think the puzzle should be able to exist independent of the answer checker. If removing the checker makes the puzzle unsolvable (or at least not something you can solve uniquely), that feels inelegant to me.
LikeLiked by 1 person
Do you consider this puzzle to be inelegant for the reason you stated? https://2018.galacticpuzzlehunt.com/puzzle/the-answer-to-this-puzzle-is.html
LikeLike
That’s clearly an exception, since the puzzle itself is ABOUT the answer checker. (I actually considered mentioning that puzzle in my comment, but I didn’t think it would be necessary to clarify.)
LikeLike
I broadly agree with what Dan is saying (a puzzle should be solvable independent of an answer checker) but I don’t think it applies to the BEATLES example. If a puzzle solved to ONE OF THE PLANETS and then you had to use the answer checker to figure out which one… that’s definitely not kosher. But if you’ve identified the very specific thing the constructor was going for, but you’re just not certain how he phrased it – I think that’s a different story.
Serious question. If this puzzle existed in isolation (an NPL handout let’s say; no meta, no answer checker) and you’d extracted the phrase BAND WITH JOHN PAUL GEORGE RINGO, would you really feel the puzzle was incomplete/inelegant because you couldn’t be sure whether or not the constructor wanted the THE?
I think that’s my personal smell test. If a puzzle would feel complete in an isolated context, then the elegance check has been passed. If the particular circumstances of the puzzle hunt require a specific way of expressing the answer, then that can be communicated to the solver anyway I want without compromising the inherent elegance of the puzzle.
LikeLike
I totally agree with you for a standalone puzzle. But if the puzzle’s part of a puzzlehunt, in which the answer likely feeds into a metapuzzle, the distinction between BEATLES and THE BEATLES could matter, and I still don’t think it should require answer checker functionality to see which one you should be using.
LikeLike
If you’re saying that your main dissatisfaction is about figuring out which answer to feed into the meta, then you’re not actually complaining about the *puzzle* being inelegant, you’re complaining about the connection between the puzzle and the meta being inelegant — the “feeding process”, such as it is.
Nobody has actually brought up the possibility that the answer checker could just simply accept both “THE BEATLES” and “BEATLES” and then the meta could have the statement “When using the answer from the puzzle ‘Absolutely Fabulous’, please use the seven-letter answer” but it seems like a reasonable thing to do as well (perhaps with many differences of opinion as to how elegant that would be).
Metaphorically, it’s like realizing that a plug doesn’t fit into a socket and therefore you need to add an adapter. If you glue the adapter to the plug, then the plug looks ugly. If you glue the adapter to the socket, then the socket looks ugly. If you just supply an unattached adapter, then the whole process looks ugly. Erin seems to be saying that the adapter should be glued to the plug and then the the plug-adapter combination should then be prettied up. Asher seems to be saying that the plug by itself seemed fine, and since we’re building a master-conversion-board anyway why not just glue the adapter onto that. Dan seems to be saying that *something* is ugly but he doesn’t care how it’s fixed, just fix it somehow.
It’s pretty easy to come up with other examples of different puzzle answers, different answer checkers, different metas, and different feeder rules that all combine in different ways and we could probably find wildly different opinions as to what’s inelegant vs what’s cute. In the Google Puzzle Hunt we had some “feeders” that were 8×8 bitmaps, but fortunately we didn’t think we needed an answer checker for those. We also had some “feeders” that were French Impressionist paintings and there our answer checker accepted almost all spellings of the painting names. I’m sure that if one used an audio-only answer checker (such as an old-style phone system), one could play with puzzle answers that had unique sounds but ambiguous spellings. And so on.
I would say that, my personal opinion is that I’d hesitate to make any general statements about whether the inelegance should be patched on the puzzle side, the interface, or the meta side. Stuff like that can be looked at on a case-by-case basis. But if the puzzle side is pretty elegant, and the meta side is pretty elegant, then I can see a good argument to just keeping that inelegance in the answer checker.
LikeLike
A couple things I said in my survey and will say here even though I don’t have to.
Not sure I speak for everyone who “misses the answer callbacks,” but what I think I really miss is the regular human contact with HQ throughout hunt. The answer check system has changed a lot (it used to involve picking up an actual phone and calling a number) and can continue to change, but I hope there remains some open line of communication between HQ and all the teams, however difficult that is to maintain with the huge number of teams.
Second, and I fully expect hate mail for this, in the hubbub over the overnight shutdown (I’m agnostic about whether it’s worthwhile or practical to enforce when people sleep) I did wonder if a “lull time” might encourage smaller teams a little bit. HQ can always create a natural check on team size by throttling the number of puzzles available at once, but in a 24-hour hunt competitive teams will tend to be a little bigger than they need to be to run “shifts” to maintain continuous solving pace. You can’t control when people solve, but pausing new puzzle releases/interactions for a period of time overnight could encourage teams to break at the same time and maintain “full strength” otherwise, minimizing the need for overlapping shifts and mitigating the FOMO that can otherwise keep solvers up until they crash. Just a thought.
LikeLike
Re human contact: it took me a while into hunt before I realized that LO was very responsive over email! Email always feels a little difficult during hunt (I tend to not check mine much, and some past organizing teams have had spam filter issues etc with incoming mail), so for things that I would have requested an HQ call for in the past I didn’t even bother to email. Left Out did quite well here but if future teams plan to have a well staffed contact email it would be great to emphasize that it is in fact well staffed 🙂
LikeLike
Regarding the forced lull… my first question is, when do you enforce the lull? A team full of MIT students during IAP (or west coast solvers) is going to be amped up and ready to solve until at least 3-4 am. They are going to have their natural dead time from about 6 am-10 am.
A team full of 40 year old east coasters might want to go to bed at midnight and be ready to start again in the morning at 7 am… right when the first team is going to bed and wants their natural break.
I can only imagine the resentment if a bunch of MIT students are told by a bunch of old crusty people that they have a curfew. (They will, in fact, just keep solving whatever they have open, even if they can’t confirm answers.)
LikeLike
I’m not worried so much about student teams, who (regardless of “policy”) will (and should) stay up and go to bed whenever they want and unless they are solving super-aggressively, should have enough puzzles to work on at all hours.
I was thinking more about the advantage that the uber-large teams have when puzzles are released on a continuous 24-hour basis, because they can effectively work as multiple teams trading off (also true of “networked” teams with sub-bases of people coordinating in different parts of the world). Maybe that’s OK but I think it’s part of the incentive for competitive teams to “bulk up,” which contributes to the ongoing escalation in the size of the hunt overall.
There might not be an effective way to counterbalance that without annoying some set of teams that are on a different circadian rhythm from the rest, though if I had to choose the “operating hours” I would prioritize MIT student schedules rather than senior citizens like us.
LikeLike
I understand this has VERY little to do with how hunt should be run, but some of my teammates and I chose not to be spoiled on the puzzles and metas for the “Experimental” rounds and have been slowly solving them in the months since hunt. This has kept us happily busy, so it’s hard for me to say that there were “too many” puzzles – they are not wasted. Really, are excellent quality too. So hopefully this is of benefit to the presumptive target of hunt, smaller MIT-rich teams that can continue to enjoy the hunt puzzles outside of hunt weekend.
LikeLike